Current Research Projects
AI-Driven ADHD Management
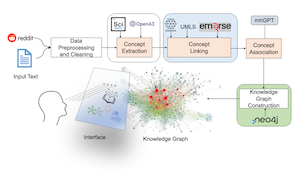
ADHD, a widespread condition, is currently the focus of one of our ongoing projects, where we are actively working and developing innovative solutions. This project aims to revolutionize ADHD management by leveraging cutting-edge AI techniques to analyze a wealth of information from various sources. Using natural language processing, knowledge graphs, and deep learning models, we are in the process of developing novel AI-powered tools. Additionally, we are constructing an ADHD knowledge graph that will offer a comprehensive view of the disorder and its treatments, potentially leading to technological innovations for public health conditions and the development of new interventions with fewer negative consequences.
Deep Multi-Modal Data Fusion
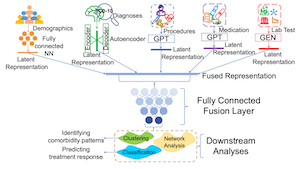
We are actively working on the development of a groundbreaking multi-modal data fusion approach powered by generative AI techniques. This innovative method is designed to seamlessly integrate and analyze diverse data types related to ADHD and its comorbidity, including demographics, diagnoses, and medication history. We are in the process of building and implementing this state-of-the-art generative AI-based multi-modal data fusion approach. Our dataset encompasses a total of 699,986 unique patients, including those with ADHD, control individuals, and various comorbidities, with a special emphasis on 55,000 cases of ADHD comorbidity with mental health conditions sourced from the TriNetX global health research network. This ongoing effort is poised to advance our understanding of comorbidity in ADHD and enhance its management.
Uncovering Language Disparities in Pediatric Health Records
In this project, we investigate the impact of stigmatizing language in the pediatric health records. Using innovative Natural Language Processing techniques, we analyze clinician notes to uncover racial, ethnic, and language-related disparities. Our research aims to create innovative approaches to better understand healthcare inequities. By exploring associations with clinical outcomes, we aim to inform policies and practices that promote unbiased and equitable pediatric care, advancing our mission to ensure optimal healthcare for all.
Fitbit Metrics to Predict ADHD

As part of our another current projects, we are actively exploring the interplay between physical activity and ADHD, utilizing the latest in wearable technology. With data from the ABCD study, we are investigating potential associations between Fitbit-derived measurements and ADHD. We are also in the process of developing models and machine learning classifiers to assess their predictive capabilities in relation to ADHD. This project underscores the promising role of wearable technology in advancing our understanding of ADHD and its potential diagnostic applications.
Distinguishing ADHD and Anxiety in Social Media Posts
Distinguishing ADHD from Comorbid Anxiety Disorders is a challenging task. We are working to differentiate between ADHD and anxiety in individuals who exhibit symptoms of both conditions. To achieve this, we analyze linguistic markers in self-reported Reddit users' posts from different subreddit categories, including ADHD, anxiety, ADHD comorbid with anxiety, and a non-mental health control group. Our approach incorporates Latent Dirichlet Allocation (LDA) topic modeling and Bidirectional Encoder Representations from Transformers (BERT) to extract relevant features. Machine learning models, such as Support Vector Classifier (SVC) and Logistic Regression (LR), are trained to distinguish between ADHD and anxiety. Our project holds the potential to provide valuable tools for clinicians to better understand and differentiate these mental health conditions.
Previous Research Projects (Selective)
Twitter Corpus of the #BlackLivesMatter

Black Lives Matter (BLM) is a decentralized social movement addressing violence against Black individuals, particularly police brutality. Gaining prominence in the wake of the Ahmaud Arbery, Breonna Taylor, and George Floyd tragedies in 2020, the #BlackLivesMatter hashtag symbolizes this grassroots movement, while counter hashtags like #AllLivesMatter and #BlueLivesMatter represent alternative perspectives. We've compiled a dataset of 63.9 million tweets from 13.0 million users across 100 countries containing keywords BlackLivesMatter, AllLivesMatter, and BlueLivesMatter. Spanning from 2013 to 2021, this dataset enables the examination of temporal trends in keyword usage and the creation of Latent Dirichlet Allocation (LDA) topics for linguistic pattern analysis, assisting researchers in exploring these important conversations.
Substance Use and Reward Processing in Adolescents
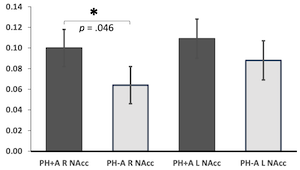
In this study, we examined the relationship between parental substance use history and reward system functioning in pre-adolescents (aged 9-10) from the Adolescent Brain Cognitive Development (ABCD) Study, with a specific focus on nucleus accumbens (NAcc) and putamen activation. Unlike prior research, we prioritized a large, substance-naïve sample to address previous limitations. The study included 10,622 ABCD participants, with parent-history-positive (PH+) individuals having one or both biological parents with a history of alcohol (PH+A) or other drug (PH+D) issues. Results revealed that PH+A youth exhibited increased right NAcc activation during large reward anticipation, while PH+D youth showed enhanced left putamen activation. Bayesian hypothesis testing provided moderate evidence supporting these findings. This research shed light on the subtle distinctions in reward processing among pre-adolescents with parents having substance-related problems compared to their peers.
Robust Document Representations
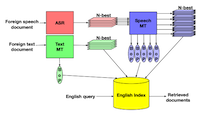
Cross-lingual information retrieval (CLIR) aimed to find relevant documents in languages different from the query. Dealing with translation errors, especially in low-resource settings with limited training data for machine translation (MT) and bilingual dictionaries, was a major challenge for CLIR. The presence of speech documents introduced additional errors through automatic speech recognition (ASR). We proposed a robust document representation that combined N-best translations and a novel bag-of-phrases output from different ASR/MT systems. We conducted a comprehensive empirical analysis on collections containing Somali, Swahili, and Tagalog speech/text documents to be retrieved by English queries. Comparative evaluations of ASR/MT systems with varying error profiles consistently demonstrated that an enriched document representation effectively addressed issues stemming from low translation accuracy in low-resource CLIR settings.
Large and Complex Document Understanding
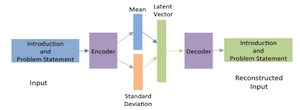
Understanding extensive, structured documents such as scholarly articles, proposals, or business reports was a complex undertaking. It required uncovering the documents' primary purposes and subjects, deciphering the functions and meanings of their sections and subsections, and extracting detailed entities and associated facts. In our research, we introduced a deep learning-based document ontology that captured the general-purpose semantic structure and domain-specific concepts from a vast array of academic articles and business documents. The ontology described different functional elements within the documents, thereby enhancing semantic indexing for improved comprehension by both humans and machines. We evaluated our models through extensive experiments using datasets of scholarly articles from arXiv and Request for Proposal documents.